 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate N-Gram Markov Model for Natural Language Generation
Aug 24, 1994This paper proposes an Approximate n-gram Markov Model for bag generation. Directed word association pairs with distances are used to approximate (n-1)-gram and n-gram training tables. This model has parameters of word association model, and merits of both word association model and Markov Model. The training knowledge for bag generation can be also applied to lexical selection in machine translation design.
A Corrective Training Algorithm for Adaptive Learning in Bag Generation
Jul 06, 1994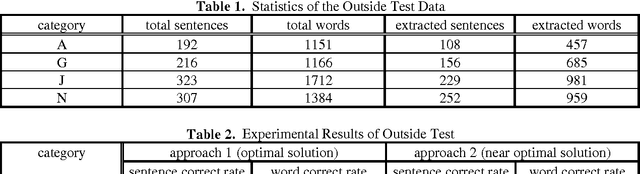
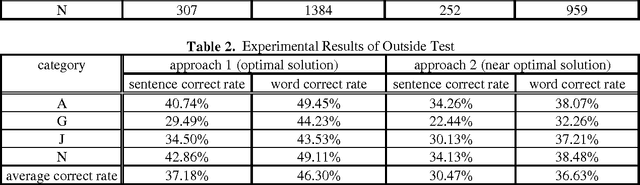
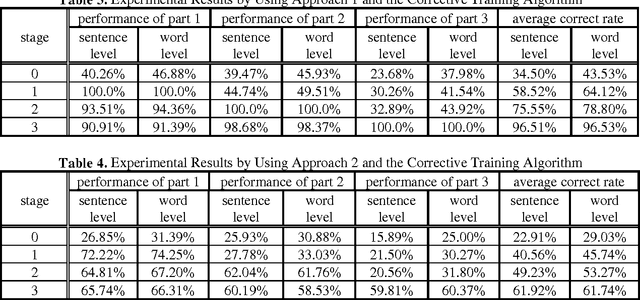
The sampling problem in training corpus is one of the major sources of errors in corpus-based applications. This paper proposes a corrective training algorithm to best-fit the run-time context domain in the application of bag generation. It shows which objects to be adjusted and how to adjust their probabilities. The resulting techniques are greatly simplified and the experimental results demonstrate the promising effects of the training algorithm from generic domain to specific domain. In general, these techniques can be easily extended to various language models and corpus-based applications.
* 7 pages, uuencoded compressed PostScript file; extract with Unix uudecode and uncompress